Action
Forging a Unified Strategy: User Needs at the Core
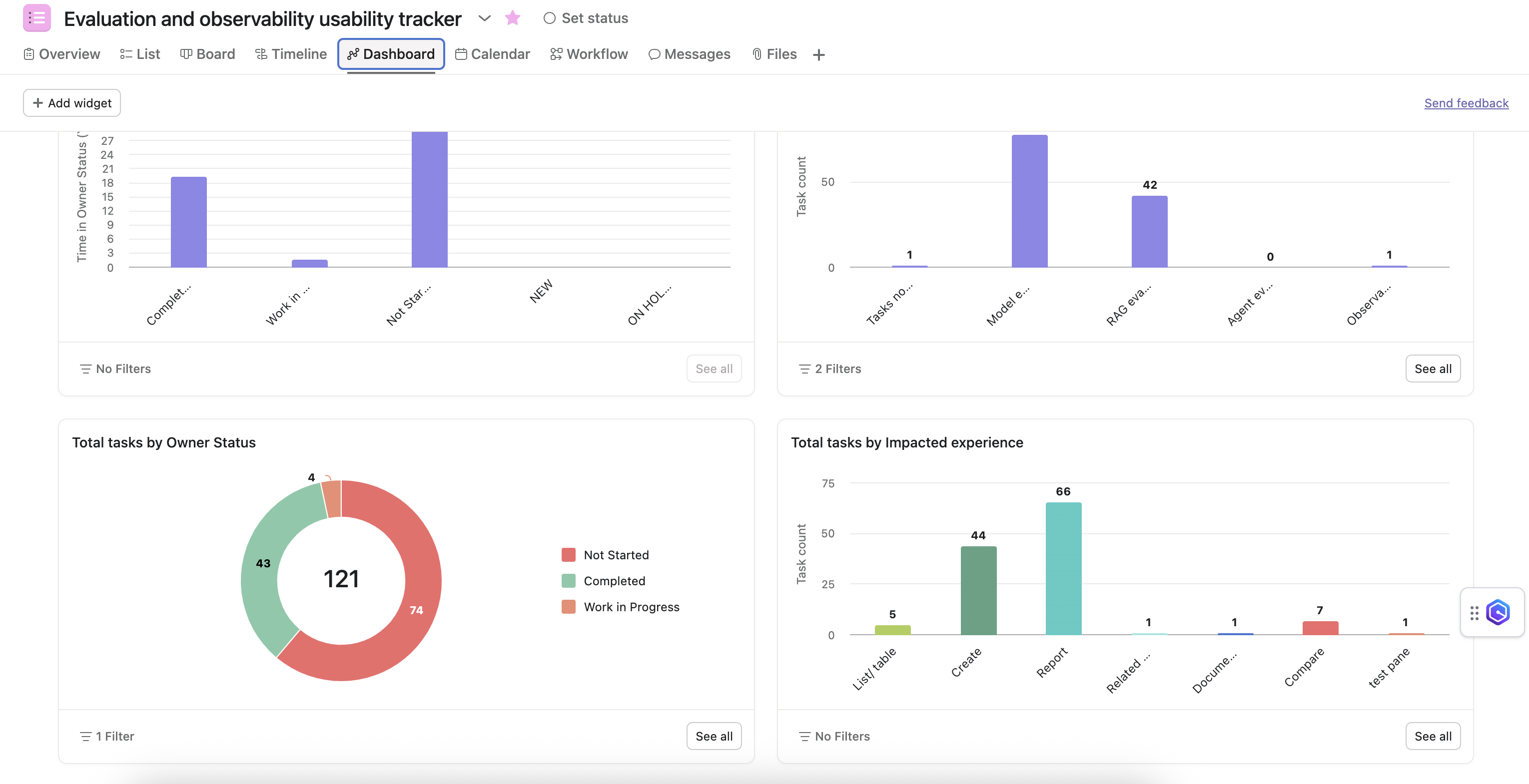
To transform a failing feature into a cohesive platform solution, I knew we needed both deep user understanding and strong team alignment.
Comprehensive research initiative:
- survey with 250+ participants
- 31+ customer interviews
- Console telemetry analysis
- Rapid prototyped and tested solutions
2 day workshop with 80+ participant:
Research alone wasn't enough to align teams pulling in different directions. I partnered with the HIL designer to run a foundational 2-day workshop, bringing together 80+ participants across Bedrock, Q, HIL, and SageMaker.
Using sprint-style UX activities, we forced teams to revisit the basics: Who are our users? What do they actually need? What are we really solving for?